🍊
KL3M,
the first clean LLM.
Language models without IP or toxicity issues.
🍊 KL3M
How is KL3M trained?
KL3M is a family of models built on a shared set of training data principles.
Clean provenance
🍊 We know where every word in our training data came from and have clear documentation to support it.
High-quality content
🍊 KL3M is trained on content that is higher quality than the vast majority of the Internet.
No copyright issues
🍊 KL3M doesn't rely on "fair use" or violate copyright.
No breach of contract
🍊 KL3M doesn't "scrape" websites in violation of their terms of services or use policy.
No LLM synthetic data
🍊 KL3M does not contain synthetic data generated by other models like GPT, Claude, Llama2, or Mistral.
No toxic sources
🍊 KL3M does not contain data from sources that are known to be toxic.
Fairly Trained
KL3M is the first language model to obtain the Fairly Trained L Certification.

This means that we have successfully demonstrated our compliance with the requirements for this certification, and that users can trust that KL3M has been trained in a way that respects the rights of content creators and rightsholders around the world.
Technical Comparison
How does KL3M compare?
Early Results
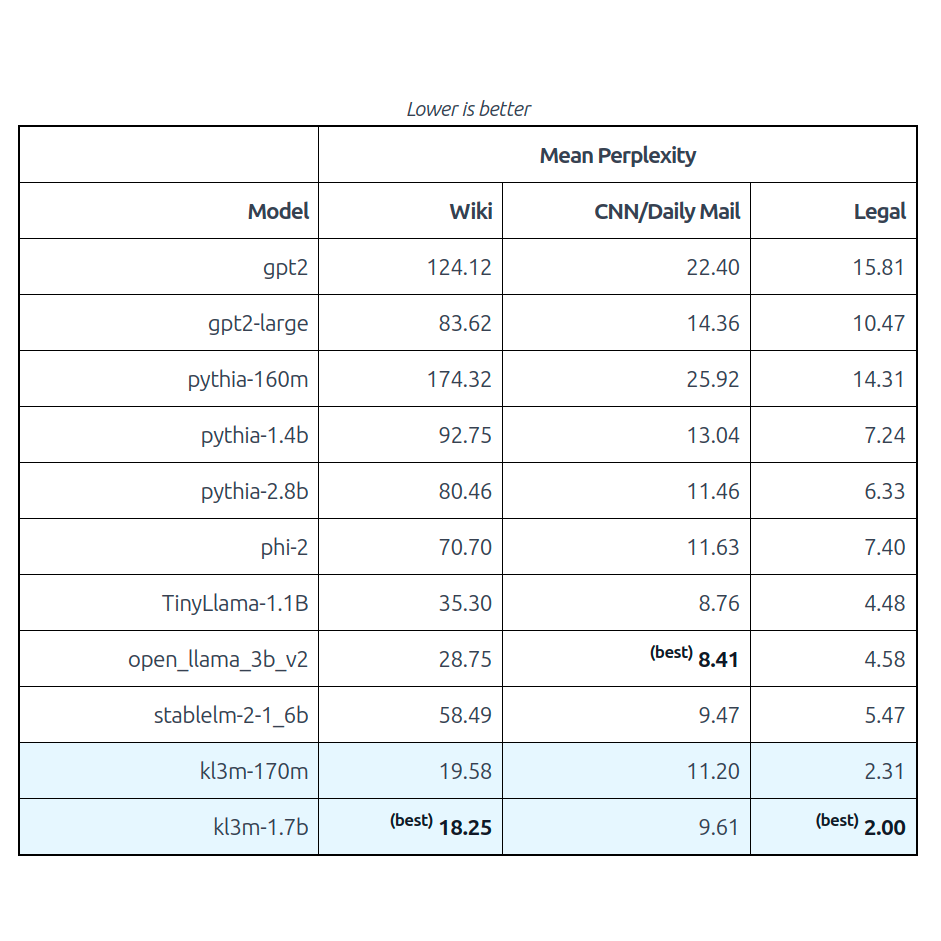
Our first two models,kl3m-170m and kl3m-1.7b, are the most efficient base models we've tested on "business" content like legal and financial material.Best-in-class perplexity on legal domain data.
Even the 170M parameter model outperforms models with 10x the parameters.
Excellent performance on general material like news articles and encyclopedia content.
Technical Comparison
Toxicity and Bias ☢️
Toxic In, Toxic Out
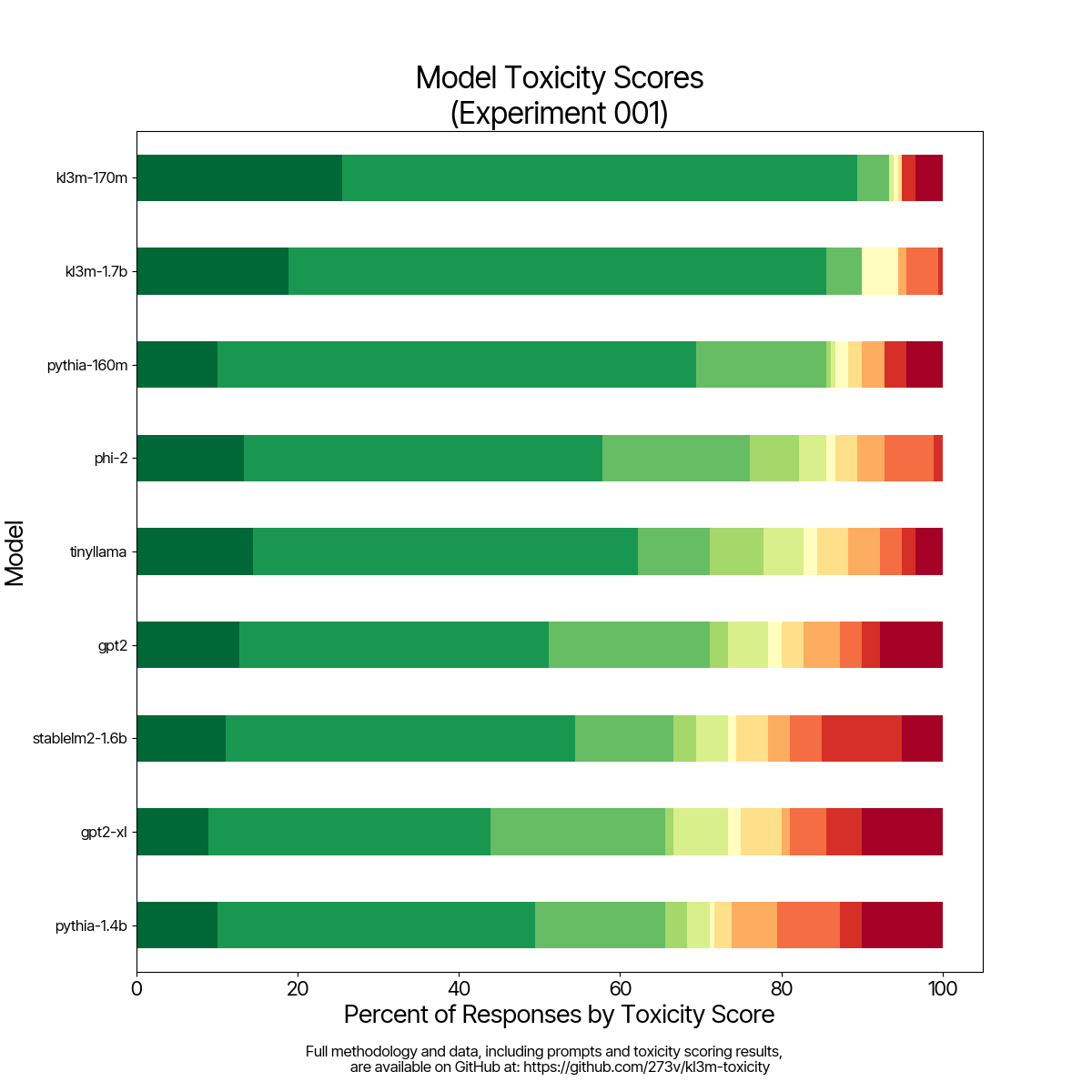
Our first two models,kl3m-170m and kl3m-1.7b, are the cleanest models we've tested.Lowest rate of "bad" words like curse words or slurs.
Lowest mean and median toxicity scores tested.
Open source research for you to review.
Already in Use
Invoices and Time Entries
Drafting and revising time entries and invoices.
Contracts
Drafting and revising contract clauses.
SEC Filings
Drafting and revising SEC filings like 10-K and 8-K report sections.
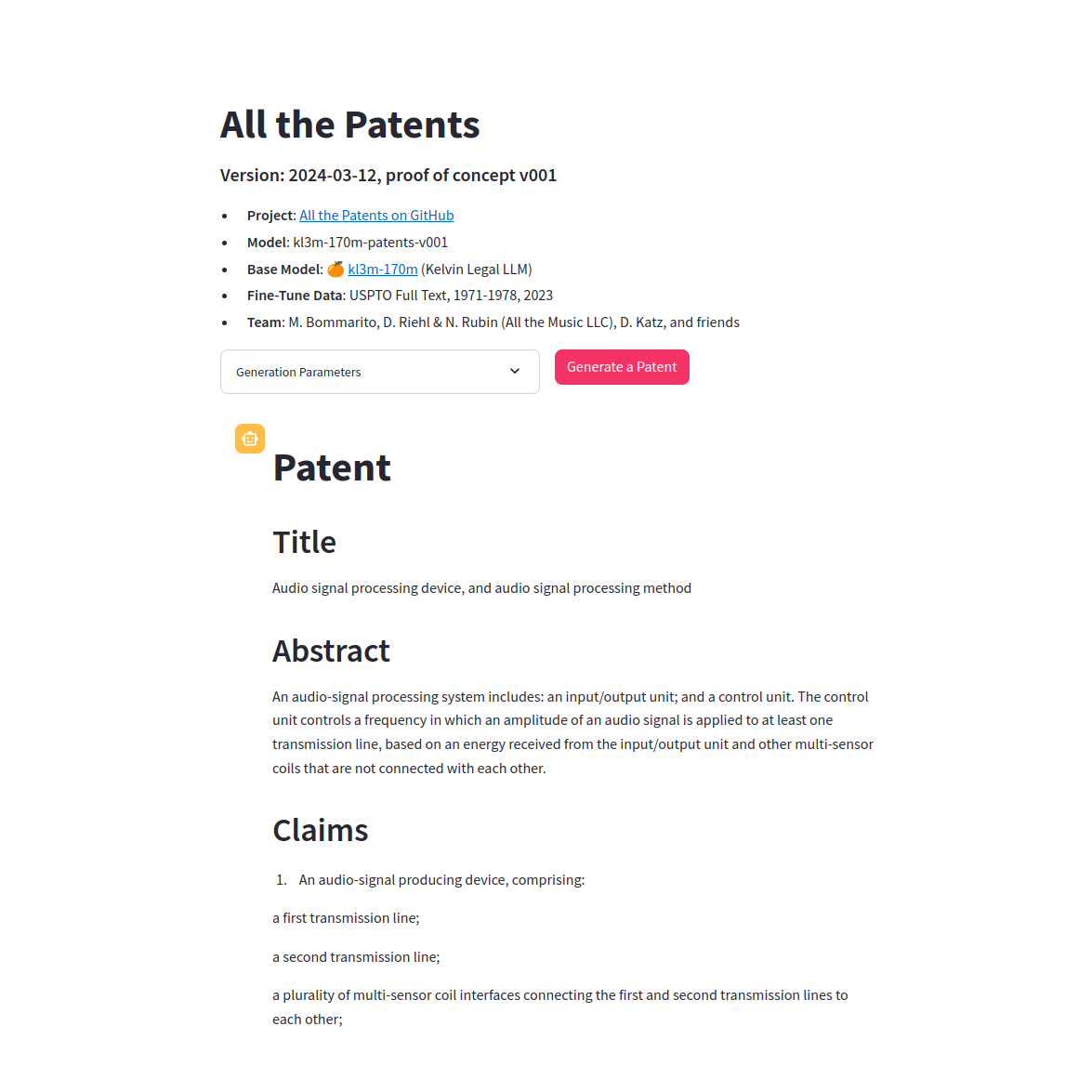
All the Patents
Drafting obvious patents as part of the All the Patents project.
What can you do with KL3M?
Continue training KL3M on your own content library
Use KL3M as a pretrained checkpoint to continue pretraining a foundation model for your own content.
Fine-tune KL3M for safe conversational AI
Use KL3M as a starting point for fine-tuning a conversational model free from copyright and toxicity issues.
Fine-tune KL3M for specific tasks
Fine-tune KL3M with your own instructions or tasks to create safe, efficient models for your specific needs.
License training data
License KL3M's 2.5T+ underlying training data in raw or tokenized formats for your own use.
Current Models
kl3m-170m | kl3m-1.7b | kl3m-3.7b* | |
|---|---|---|---|
| Parameter Count | 170 million | 1.7 billion | 3.7 billion |
| Minimum Hardware | MacBook Air M1 | RTX 3060/4060 | RTX 3090/4090 |
| Architecture | neox | neox | mixtral (x4) |
| Context Window | 4,096 tokens | 8,192 tokens | 8,192 tokens |
| Tokenizer | 32,768 (English) | 32,768 (English) | 32,768 (English) |
* kl3m-3.7b will be available in April (2024). | |||
FAQs
Frequently Asked Questions
What kind of hardware do I need to run KL3M?
The first KL3M models have been designed with accessible use as a priority. kl3m-170 runs quickly on a MacBook Air M1, and kl3m-1.7b runs well on a $300 consumer GPU.
What architectures are your models?
Smaller KL3M models are trained using the GPT-NeoX architecture. Larger KL3M models are trained using the Mixtral Mixture-of-Experts architecture (trained from scratch).
How can I run KL3M?
KL3M is distributed as standard PyTorch model weights. KL3M architectures are supported for both HuggingFace transformers and vllm for inference.
Which languages are supported?
kl3m-170m and kl3m-1.7b have both been trained on a predominantly English-language content. Larger models include content in English, Spanish (es-ES and es-MX), French, and German. We are working on adding more languages.
Do you provide an API?
Not yet. Our focus has been on enabling the use of small, local LLMs for information security and accessibility purposes, but we are evaluating the possibility of providing an API in the future.
Is it easy to fine-tune KL3M?
We have had excellent results fine-tuning KL3M on a number of use cases, including drafting, summarization, and classification. You can fine-tune kl3m-170 and kl3m-1.7b on consumer hardware.
How many tokens do you have?
We have collected over 2.5 trillion tokens of training data, and we are constantly adding more. Our training data is a mix of public domain and explicitly licensed content.
How many tokens have your models seen?
kl3m-170m and kl3m-1.7b have been trained on approximately 350B tokens of primarily English-language content. Larger models are being trained on between 500B to 1T tokens of content in English, Spanish, French, and German.
Do you have a conversational chat model?
Not yet. While our pretraining data does include a number of conversational sources, we have not yet trained a model that is designed for standard conversational rounds. Stay tuned.
Do you have a general instruction-aligned model?
Our base models already support a number of tasks like extractive/abstractive summarization or conversion, but we have not trained an open-ended model. Our first instruct model supports legal drafting and revision, and we'd love to hear what other tasks you'd like supported.
How do you pronounce KL3M?
As the 🍊 suggests, KL3M is pronounced like "Clem" or "Klem."
Why is it named KL3M?
KL3M was originally short for the Kelvin Legal Large Language Model, KLLLM. Because we're nerds, we shortened all those Ls to L cubed or L3, then shortened K-L3-M to KL3M.